# Scalability
# Describing Load
服务如何应对增长的负载。描述负载如 request per second - web server | ratio of reads to writes - database | hit rate - cache.
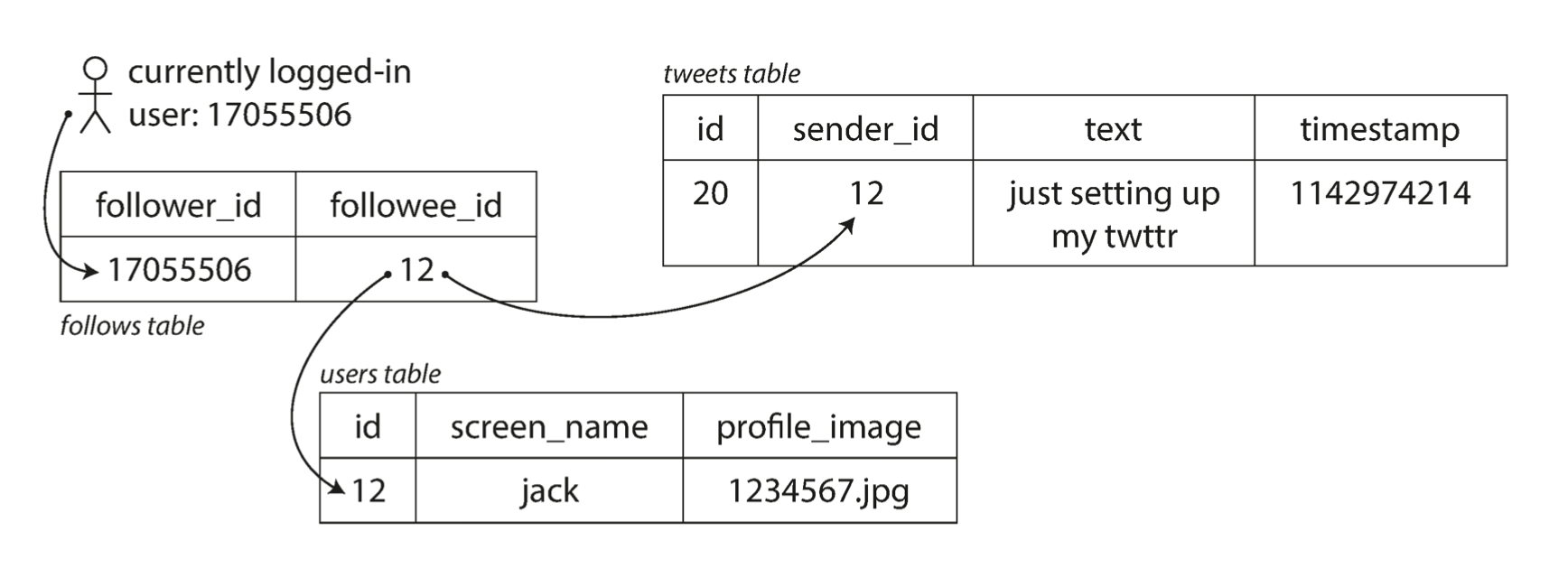
这里给了一个fan-out的例子,描述需要请求一定数量的其他服务来处理当前服务的请求的情况。也和工作的内容非常相关,是以 2012 年的 twitter 为例的:
- 用户发推行为的 avg 为 4.6kqps,max 为 12kqps
- 用户刷时间线的行为 300kqps
有两种方式实现这个场景
发推到全局集,用户刷时间线时,查询所有 ta 关注的用户,找到这些用户的所有推文,然后合并按时间排列
为每个用户维护一个时间线 cache,当用户发推文时,查询所有关注 ta 的用户,把推文发送到这些用户的 cache 里。这样读请求的成本就小了,因为结果被提前计算了出来。
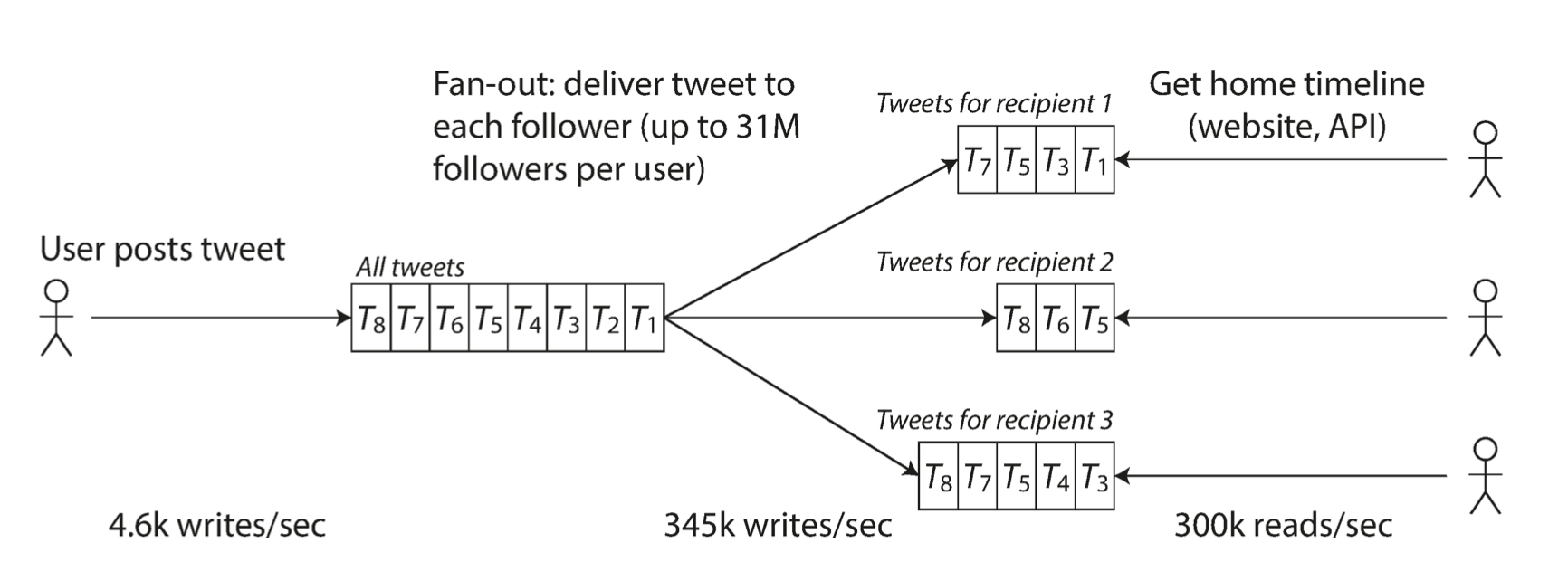
工作中还没有自己实现这么复杂的情况,可能因为业务的范围比较底层,但是有听说过“推拉结合”的做法,算是上面两种的合并版:读多写多的 key 用“拉”(方法 1),减少发送到巨量缓存的开销,实时性较好;读少写少的 key 用“推”(方法 2)来支持大量增加的读写来源。
文中推特的做法是由 1 升级到 2 来应对用户的增加,但方案 2 对于大博主来说会导致一条发文造成 million 级的写请求,很难实时地完成。所以 twitter 也用了合并两种链路的方式来让大博主的推文被单独读取和合并到时间线。
(巧了这不是)
# Describing Performance
- 增加负载,资源不变,会怎样影响性能?
- 增加负载,需要多少资源来维持性能?
工作中有时会遇到接入下游服务时需要按 qps 提供对应量的 cpu 资源的情况,算是一种维持性能的方式 所以,如果增加同样的负载,维持性能所需要增加的资源更少,这个服务是不是就有更好的 scalcbility?
对 batch process system 如 Hadoop 来说,关注 throughput 或特定大小的数据集任务完成的时间;对 online system 来说,更重要的是 response time。
response time 是客户端视角发出请求到收到返回的耗时,latency 是请求等待被处理的时间
没用过 Hadoop 赶紧查一下:https://aws.amazon.com/cn/what-is/hadoop/ Hadoop 负责存储和处理大规模数据,提供底层的分布式存储(HDFS)和计算(MapReduce)能力。 平时使用的 Hive 也是构建在 Hadoop 之上,利用 Hadoop 的存储和处理能力进行大数据处理的,并且提供了 SQL 查询接口。 除此之外还有 Spark, Pestro, HBase, Zeppelin 也是基于 Hadoop 生态的系统。
这个性能分布图的 metrics 也很常见
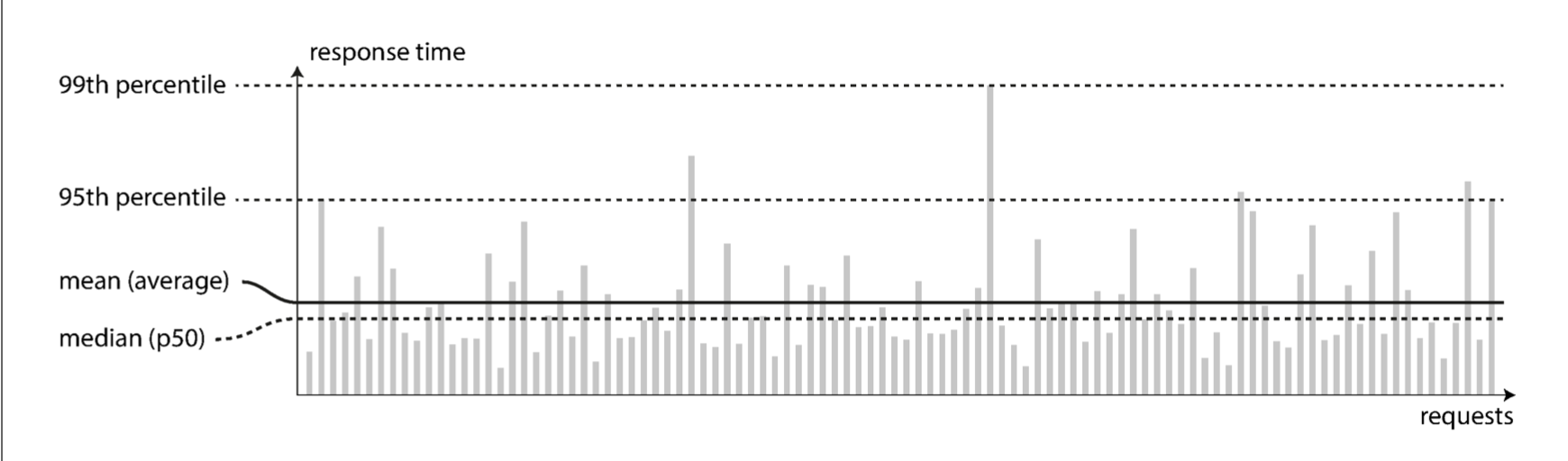
tail latency 如 p99 和用户体验直接相关(耗时最久的请求可能数据最重,所以可能是更重要的用户),但是优化的成本可能更高因为会受随机因素的影响,或者收益递减。 上游并发调用的话,最慢的一个请求会决定其下一步处理的时间
Service Level Objective 是具体的、可测量的目标,用于指导 server 和 client 之间的期望管理 Service Level Agreement 正式定义和记录服务 server 和 client 之间的服务标准和责任,通常包含一个或多个 SLO。